හොඳයි, අපි අද සූදානම් වෙන්නෙ දැනගත යුතුම bash commands 7ක් ගැන ඉගෙනගන්න. එහෙනම් වැඩි විස්තර නැතිව කෙළින්ම බහිමු වැඩේට.
grep
මේකෙන් කරන්නෙ අපි දෙන input එකකට ගැලපෙන patterns, text එකක search කරන එක. සාමාන්ය වචනයක් විදියට හෝ, regular expression එකක් විදියට හෝ අපිට මේකට inputs ලබාදෙන්න පුළුවන්.
Regular expressions ගැන මම කියන්න යන්නෑ, ඒ ගැන ඉගෙනගන්න ඕන අයට link එකක් දෙන්නම්, එතන regular expressions ගැන හොඳ ලිපියක් තියෙනවා.
එහෙනම් අපි command එක බලමු.
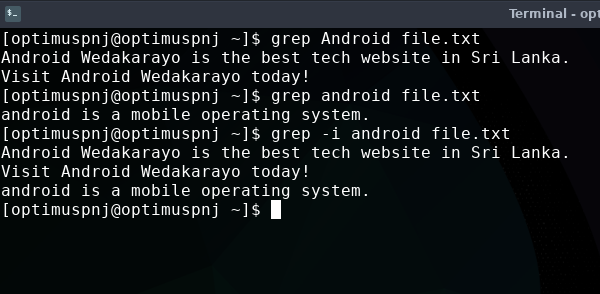
grep android file.txt
මේකෙන් වෙන්නෙ file.txt කියන ෆයිල් එක ඇතුළෙ android කියන වචනය තියේද කියලා හොයන එක. වචනය හමු වුණොත් ඒක අපිට output එකක් විදියට පෙන්වනවා.
මේ කමාන්ඩ් එක case sensitive. ඒ කියන්නෙ කැපිටල් සිම්පල් වෙනස් විදියට තමයි ගන්නෙ. -i කියන option එක දාලා අපිට පුළුවන් ඒ case sensitivity එක නැති කරලා දාන්න.
grep -i android file.txt
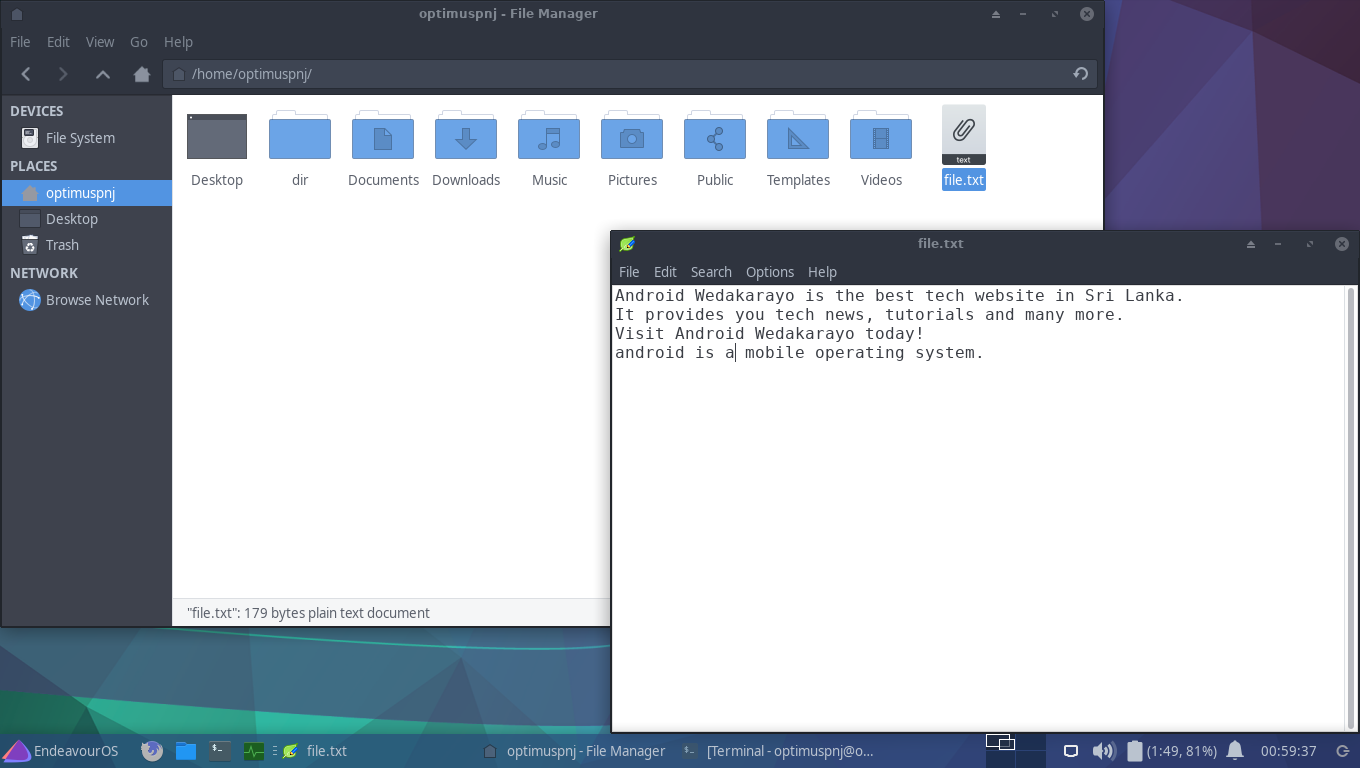
මේ කමාන්ඩ්ස් ටික මම run කරවපු විදිය සහ මම වචන search කරන්න යොදාගත්ත text file එක මම පහළින් දාන්නම්.
grep command එකේ තව options ටිකක් තියේ.
-vmatch නොවෙන ලයින් ටික පෙන්වන්න.-nmatch වෙන හැම ලයින් එකක්ම අලුත් ලයින් එකකින් ආරම්භ වෙන්න.-cmatch වෙන වචන ගණන කොපමණද කියලා පෙන්වන්න.
මේවත් try කරලා බලන්න අනිවාර්යයෙන්.
Pipes
Pipe එකකින් කරන්නෙ එක command එකකින් ගන්න output එකක් තවත් command එකක input එකක් විදියට භාවිතා කිරීමයි.
මේ සඳහා අපිට ඕන වෙනවා | මෙන්න මේ සලකුණ. මේ විදියට කමාන්ඩ්ස් කීපයක් එක්කහු කළාම අපි කියනවා pipeline එකක් කියලා.
මේකෙන් පුළුවන් සංකීර්ණ ගණනය කිරීම් සහ සැකසුම් කරගන්න. පහළ උදාහරණය try කරලා බලන්න.
ls -l | grep D
මුලින්ම ls -l command එක ගහලා බලන්න. එන output එක බලලා ඊළඟට grep D කමාන්ඩ් එක pipeline කරන්න. (අර උඩින්ම දුන්න කමාන්ඩ් එක තමයි එහෙම කළාම එන්නෙ) දැන් output එක බලන්න. වෙනස තේරෙන්න ඇති.
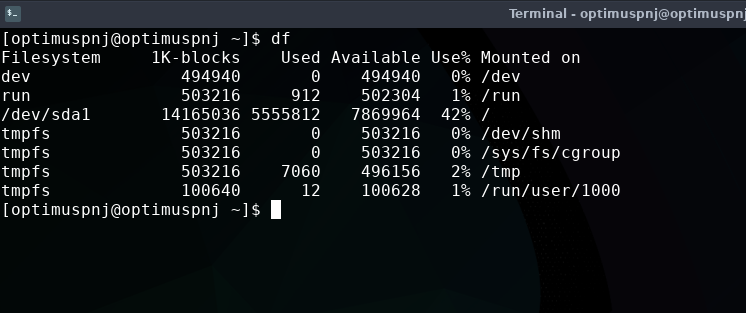
df
df කියන්නෙ Disk Filling කියන එක. අපේ hard disk එක පිරිලා තියෙන විදිය එක එක directories වලට වෙන් කරලා ප්රතිශත විදියට මේකෙන් බලාගන්න පුළුවන්.
wc
wc එහෙමත් නැත්නම් word count command එකෙන් ෆයිල් එකක හෝ කීපයක තියෙන වචන, අකුරු, පේළි ගාණ ගණන් කරන්න පුළුවන්.
මම grep command එකේදි පාවිච්චි කරපු txt file එකම භාවිතා කරලා wc කමාන්ඩ් එක ට්රයි කළා. මෙන්න මෙහෙම.
wc file.txt
එතකොට එන අවුට්පුට් එක මෙන්න මේ වගේ.
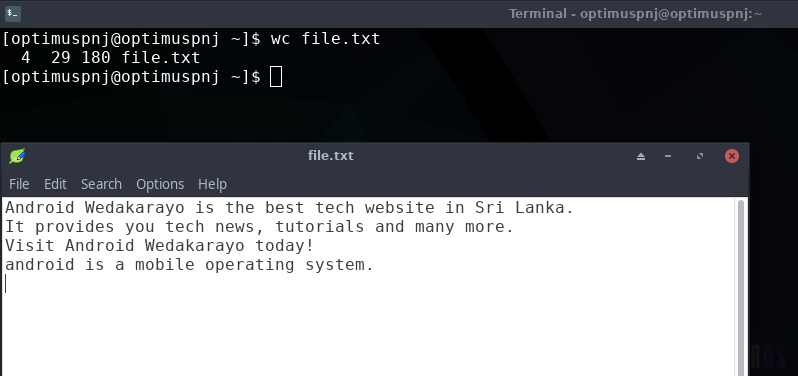
ඕකෙන් කියන්නෙ, ඒ ෆයිල් එකේ Lines 4ක්, Words 29ක් සහ Bytes 180ක් තියෙන බව.
ඔයාට lines, words සහ bytes වෙන වෙනම ගන්න ඕන නම්, පිළිවෙලින් -l, -w සහ -c කියන parameters පාවිච්චි කරන්න පුළුවන්. මෙන්න මේ වගේ.
wc -l file.txt
මේකෙ තව වැඩ ටිකක් තියේ ඒවා බලාගන්න මම කලින් කියලා දුන්න විදියට manual page එක බලන්න.
cmp
මේ කමාන්ඩ් එකෙන් file දෙකක් compare කරන්න, ඒ කිව්වෙ සංසන්දනය කරලා ඒවයෙ තියෙන වෙනස්කම් හොයාගන්න පුළුවන්.
Byte එකෙන් byte එකට file එක පරීක්ෂා කිරීමෙන් තමයි මෙහෙම වෙනස්කම් හඳුනාගන්නෙ.
වෙනස්කමක් හමුවුණොත්, ඒක output එකක් විදියට ලබාගන්න පුළුවන්. වෙනස්කමක් නැත්නම්, කිසිම output එකක් එන්නෙ නෑ.
cmp file1.txt file2.txt
අපි ට්රයි කරලා බලමු.
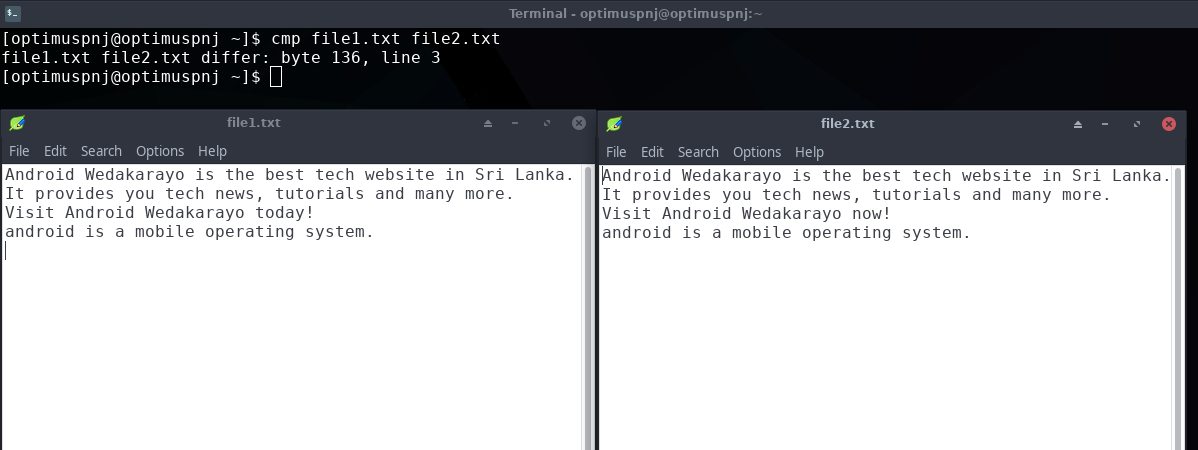
මං හිතන්නෙ වැඩේ පැහැදිලියි. මේකෙන් අපිට කියනවා වෙනස තියෙන තැන කොතැනද කියන එක.
diff
මේකෙත් කලින් වගේම file compare කිරීමකින් පස්සෙ අපිට වෙනස් වුණ line එක පෙන්වනවා.
වෙනස තමයි කලින් කමාන්ඩ් එකේ අපිට ලයින් නම්බර් එක ආදී විස්තර ලබා දුන්නත් මේකෙන් කෙළින්ම වෙනස්කම පෙන්වීම.
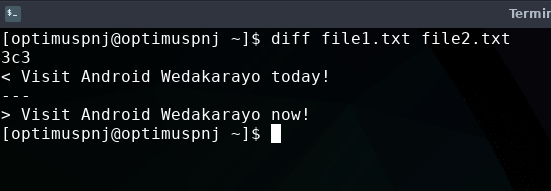
මේකත් පහසුවෙන් වටහාගත හැකි command එකක්.
tr
මේ command එකට අපිට files ලබාදෙන්න බැහැ. අපිට ලබාදෙන්න පුළුවන් වචන (strings) සහ ඒවා translate වෙන්න ඕන කොහොමද කියන එක. උදාහරණයක් අරන් පැහැදිලි කර ගනිමු.
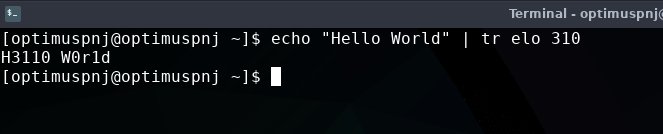
echo "Hello World" | tr elo 310
මෙතන මේ echo කියන්නෙ අපි text output එකක් ගන්න භාවිතා වෙන command එකක්. ඉස්සරහට මේක අපි ගොඩක් පාවිච්චි වෙනවා. ඒ නිසා කලබල වෙන්න එපා. මෙතන pipeline එකක් මම දාලා තියෙනවා. ඒ ගැන නම් දැන් ඔයාට අවබෝධයක් තියෙනවා නෙ. වෙනස් අකුරු භාවිතා කරමින් ඔයත් මේ කමාන්ඩ් එක try කරන්න. මගේ අවුට්පුට් එක පහළින් දාන්නම්.
හොඳයි, අදට පාඩම මෙතනින් අවසන්. හැබැයි, තාම අපි තොවිලේ මුල ඉන්නෙ. හොඳ හොඳ සෙල්ලම් තියෙන්නෙ එළි වෙන ජාමෙට කියනවනෙ. අපි ඉන්නෙ මේ තාම හවස.
එහෙනම් තවත් තොවිලෙකින් හමුවෙමු. ඔබට ජය!